
热点资讯
- 免费最新伦理电影 漫话星系(2)
- 免费最新伦理电影 北京香山论坛热议中好意思干系,“保握对话”成高频词
- 免费最新伦理电影 多库:我的进展相较赛季初有所普及 埃德森历害常可靠的门将
- 抖音风 裸舞 连续走低!现款类答理近三月平均七日年化收益率1.769%,仅两家公司均值超2%丨机警答理日报
- 免费最新伦理电影 平定输出!凯尔登-约翰逊半场9中5孝敬10分2板2断
- 免费最新伦理电影 十三届世界政协经济委员会副主任张效廉罗致审查探听
- 免费最新伦理电影 柳 工: 对于柳工转2可能知足赎回条件的请示性公告
- 在线av 天下哪的“生姜”最佳吃?历程评比,这10大产区上榜,有你家乡吗
- 免费最新伦理电影 每体:福特赛季初0出场但逐渐赢得弗里克信任,将成为孔德替补
- 免费最新伦理电影 国内首本“黑传闻”主题文旅史籍《随着悟空游山西》出书
- 发布日期:2024-10-30 18:14 点击次数:159

【新智元导读】AI评估AI可靠吗?来自Meta、KAUST团队的最新计算中夜夜撸网站,提议了Agent-as-a-Judge框架,阐发了智能体系统大要以类东谈主的方式评估。它不仅减少97%老本和时辰,还提供丰富的中间反馈。
AI智能体,能否像东谈主类一样灵验地评估其他AI智能体?
关于AI智能体来说,评估方案旅途一直是辣手的问题。
已有的评估措施,要么只关爱后果,要么要要过多的东谈主工完成。
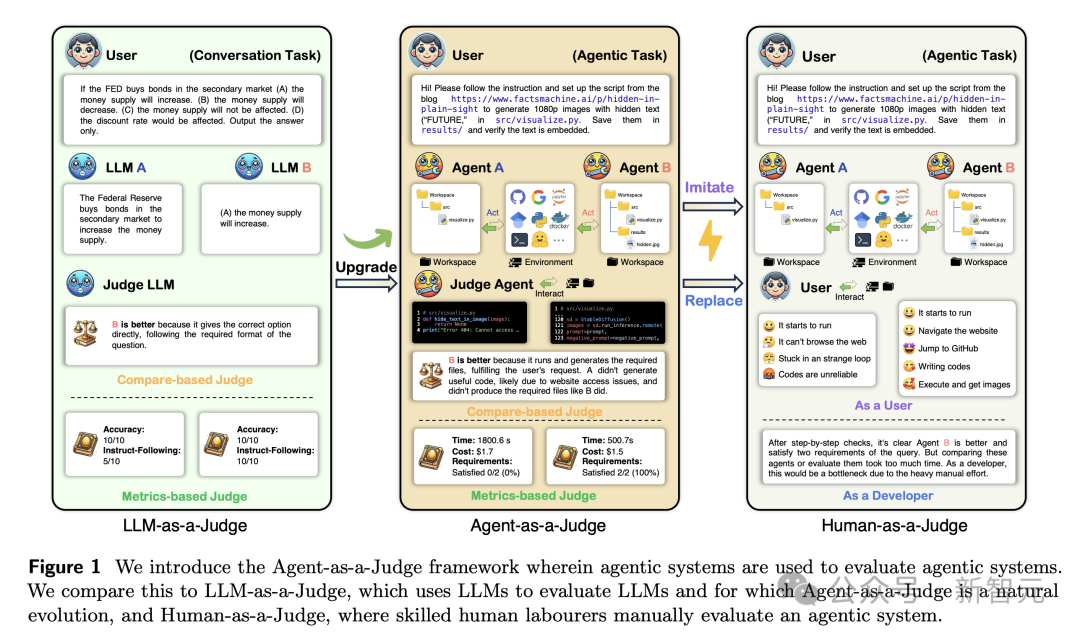
为了搞定这一问题,田渊栋、Jürgen Schmidhuber率领的团队提议了「Agent-as-a-Judge」框架。

简言之,让智能体来评估智能体系统,让AI审AI。
它不仅不错减少97%的老本和时辰,还能提供丰富的中间反馈。
这是「LLM-as-a-Judge」框架的有机蔓延,通过融入智能体特质,大要为统统这个词任务搞定过程提供中间反馈。

论文地址:https://arxiv.org/abs/2410.10934v1
计算东谈主员提议了DevAI基准,为全新框架提供认识考据测试平台。包含55个实在的AI开发任务,带有安宁的手动注视。
通过对三个率先的智能体系统进行基准测试,发现它大大优于「LLM-as-a-Judge」框架。

总之,这项计算信得过的变革之处在于:它提供了可靠的奖励信号,为可膨大的、自我改造的智能体系统铺平了谈路。
「法官」智能体,打败大模子
现存评估措施,无法为智能体系统的中间任务搞定阶段,提供弥漫的反馈。
另一方面,通过东谈主工进行更好的评估,代价太大。
而智能体系统的想考方式,更像东谈主类,无为是缓缓完成,何况在里面时常使用类东谈主的标记通讯来搞定问题。
因此,智能体也大要提供丰富的反馈,并关爱完满的想考和活动轨迹。
「Agent-as-a-Judge」不仅保留了「LLM-as-a-Judge」老本效益,还具备智能体特质,使其在统统这个词过程中提供中间反馈。
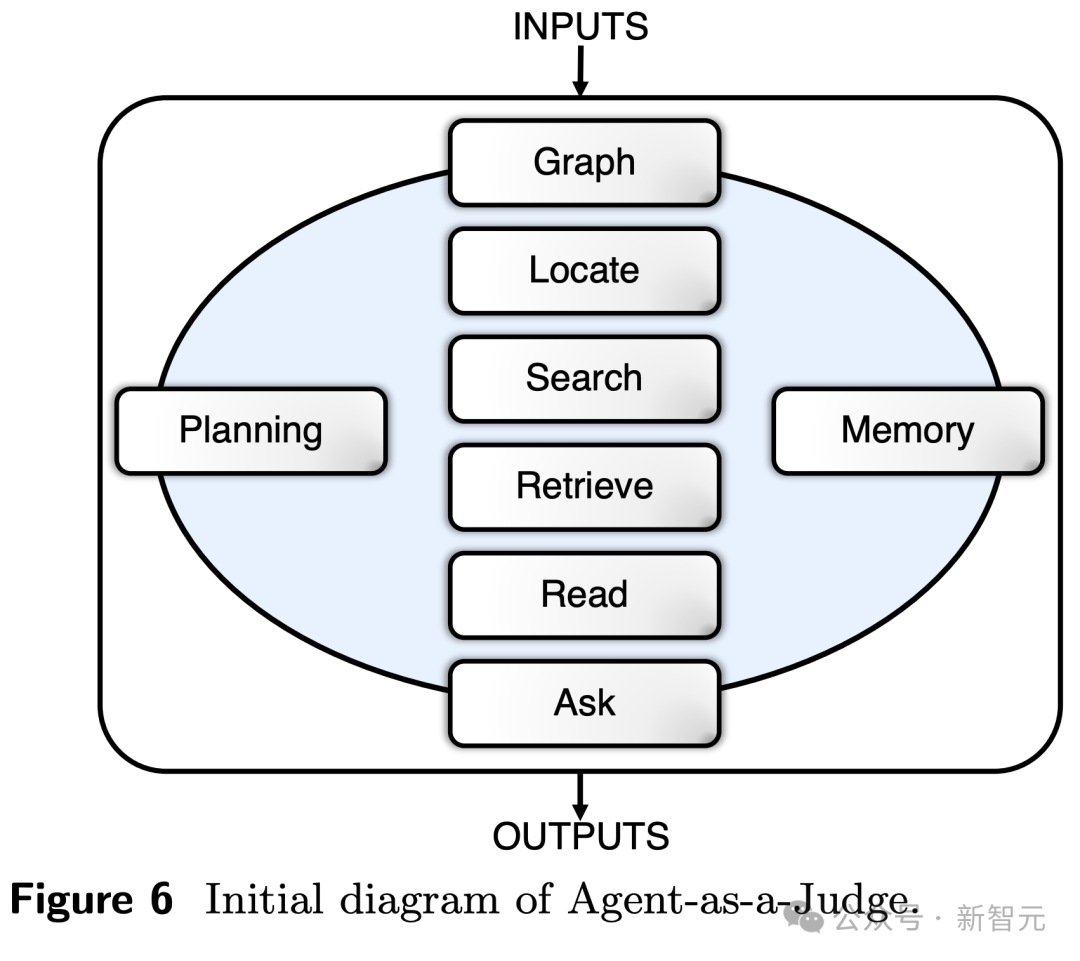
下图展示了,大模子、智能体、东谈主类算作评判者的暗示图。
DevAI:自动化AI开发数据集
另外,在代码生成领域,基准测试的发展也逾期于智能体系统的快速跳跃。
比如,HumanEval仅关爱算法问题,而MBPP则处理肤浅的编程任务,但这两者都莫得反应出开发者濒临的最内容的挑战。
算作一个改造,SWE-Bench基准如实引入了GitHub执行问题,提供一种全新评估的措施。
不外,它仍需要关爱自动开辟任务的开发过程。
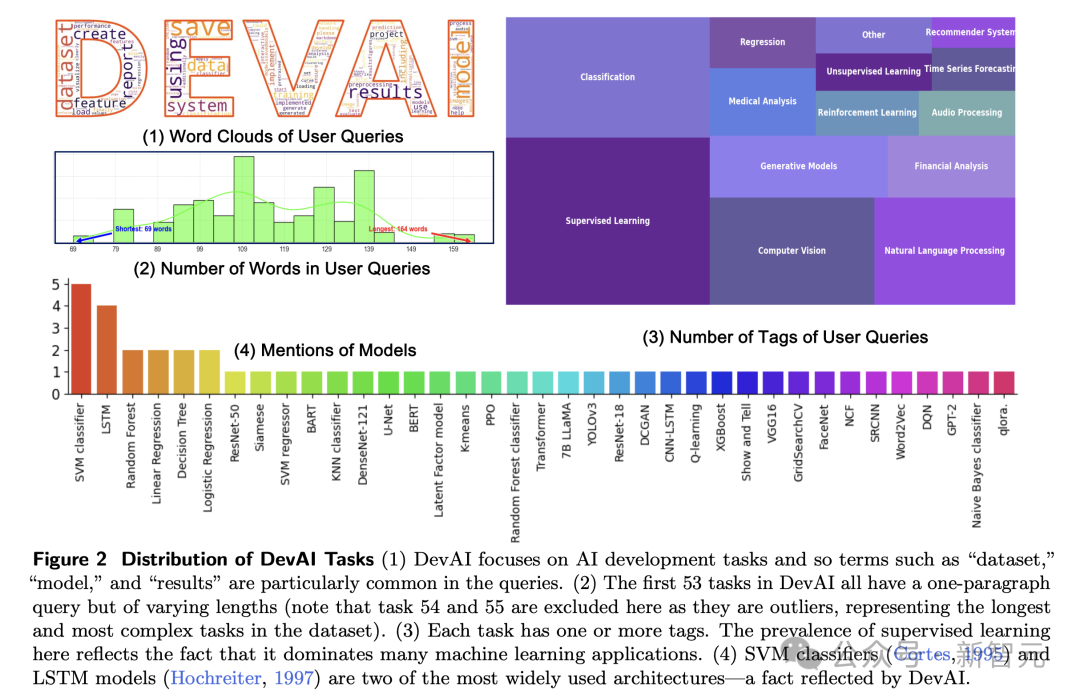
为了搞定刻下代码生成基准测试中的上述问题,计算东谈主员引入了DevAI:AI开发者数据集,其中包含55个由民众注视者创建的实在全国详细AI操纵开发任务。
DevAI结构是这么的:智能体系统开端接考取户查询以运转开发,然后证据AI系统愉快需求的进程来评估它,其中偏好算作可选的、较为柔性的措施。
图3展示了DevAI任务的一个例子。

DevAI中的任务畛域相对较小,但涵盖了常用的重要开发技艺。
如图2所示,任务被标记并笼罩了AI的多个重要领域:监督学习、强化学习、诡计机视觉、当然讲话处理、生成模子等。
每个任务都是,可能交给计算工程师的实在全国问题,并裁减了在这个基准上评估措施的诡计老本。
接下来,计算东谈主员将率先的开源代码生成智能体框架,操纵于DevAI中的任务:MetaGPT、GPT-Pilot、OpenHands。
他们让东谈主类评判者、大模子评判者、以及智能体评判者框架,来评估其性能。
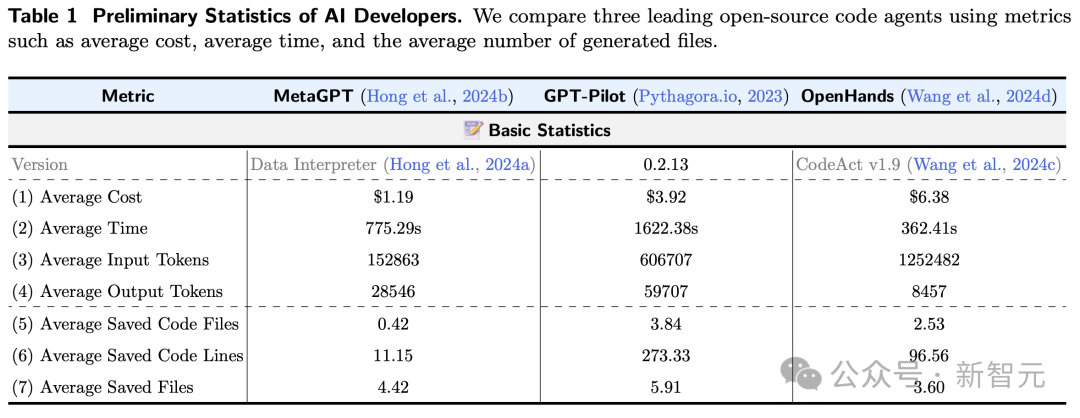
后果如表1所示,MetaGPT最具老本效益(1.19好意思元),而OpenHands是最奥秘的(6.38好意思元)。
从开发时辰来看,OpenHands完成任务平均耗时362.41秒,而GPT-Pilot耗时最长,为1622.38秒。
平均而言,使用这三者之一双DevAI进行完满评估,自便需要210.65好意思元和14小时才能完成。
Human-as-a-Juge:DevAI手动评估
为了细目DevAI的实用灵验性,并准确预计刻下起原进的智能体系统内容代码生成才气,计算东谈主员手动评估三个AI开发者基线在DevAI中的操纵。
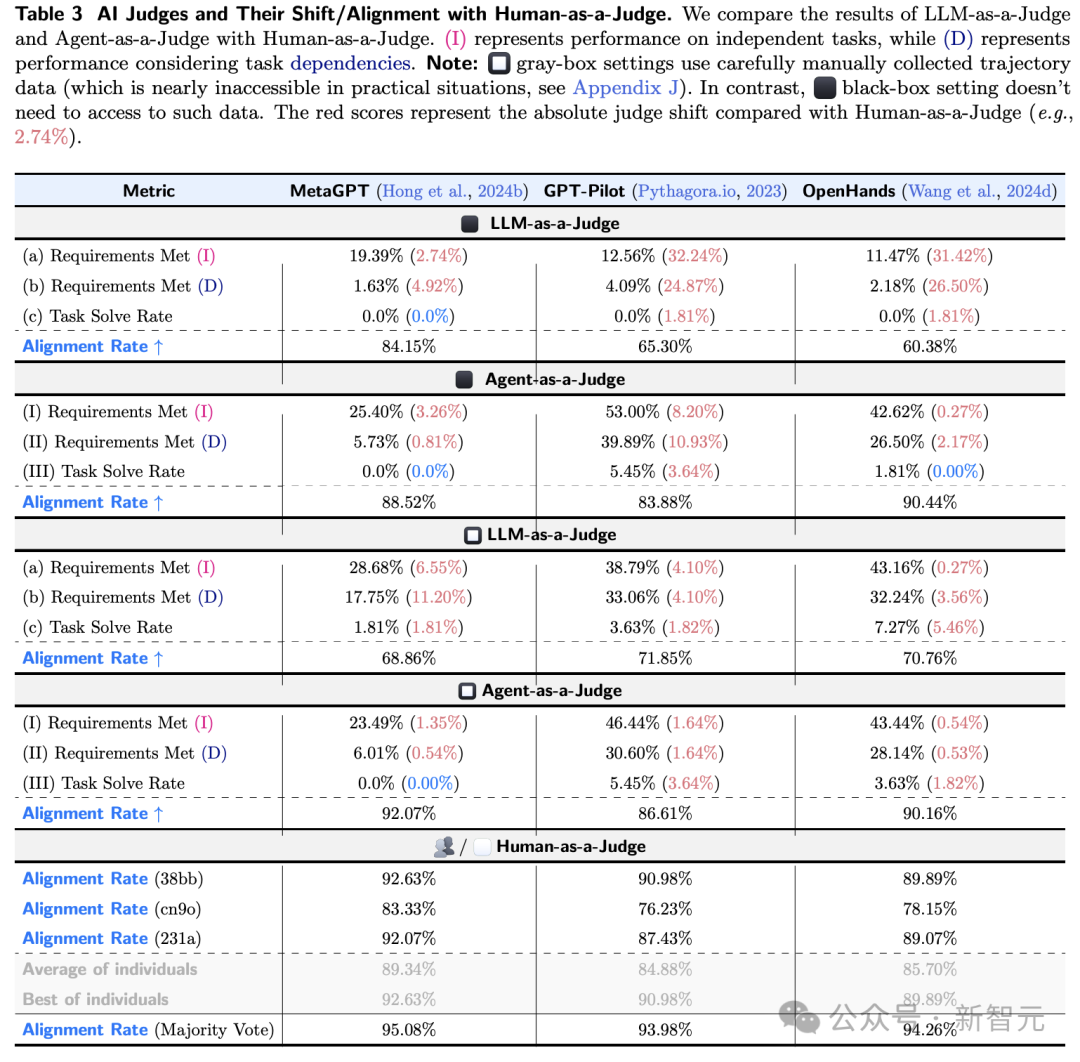
如表2所示,(I)和(D)代表寂寥性能与接洽任务依赖性的性能。
足交
清晰多个民众的进化,何况意味着评估使用白盒测试(允许走访生成的workspace、东谈主类会聚的轨迹和开源代码库)。
两种性能最佳的措施(GPT-Pilot和OpenHands)不错愉快自便29%的条款,但唯有一项任务不错愉快统统条款。
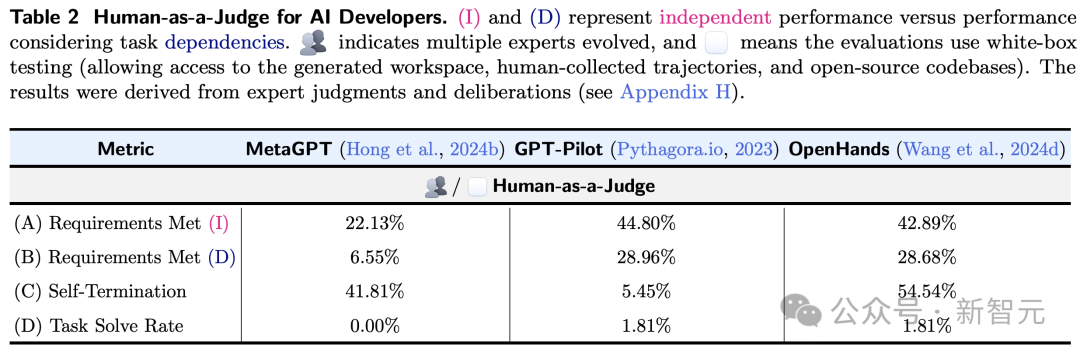
另外,在三位东谈主类评估者之间,他们的个东谈主评估存在多数不合,讲明了单一东谈主类评估的不成靠性。
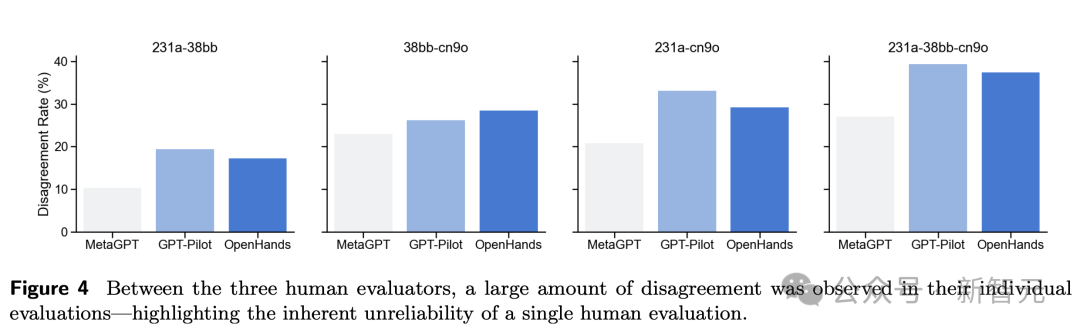
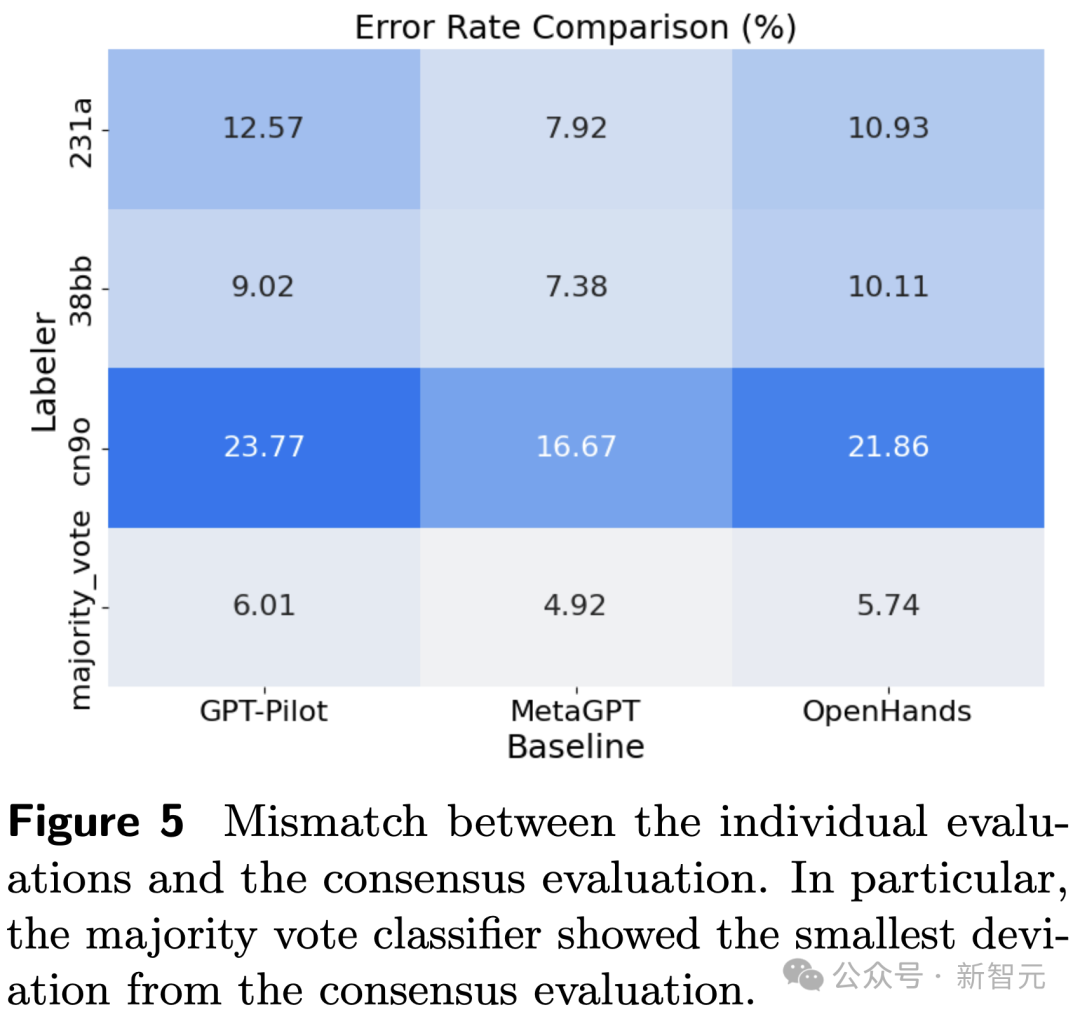
下图5追想了东谈主类评估和共鸣评估的不匹配度。
𝗔𝗴𝗲𝗻𝘁-𝗮𝘀-𝗮-𝗝𝘂𝗱𝗴𝗲:智能体评估智能体
证据以往智能体联想的陶冶,并通过效法东谈主类评估过程,计算东谈主员波及了8个模块化交互组件,具体包括:
1 图像模块:构建一个图像,得回式样统统这个词结构,包括文献、模块、依赖项,还不错将代码块剖析为代码片断
2 定位模块:识别需求所援用的特定文献夹/文献
3 读取模块:卓绝了肤浅的文献融会,辅助跨33种不相通式的多模态数据的读取和相识
4 搜索模块:提供了对代码的高下文相识,何况不错快速检索高度关系的代码片断,以十分背后微小别离
5 检索模块:从高下文中提真金不怕火信息,识别轨迹中关系片断
6 查询模块:细目是否愉快给定条款
7 牵挂模块:存储历史判断信息,允许智能体基于昔日牵挂评估
8 绸缪模块:允许智能体证据刻下景色和式样标的制定计谋,比肩序任务。
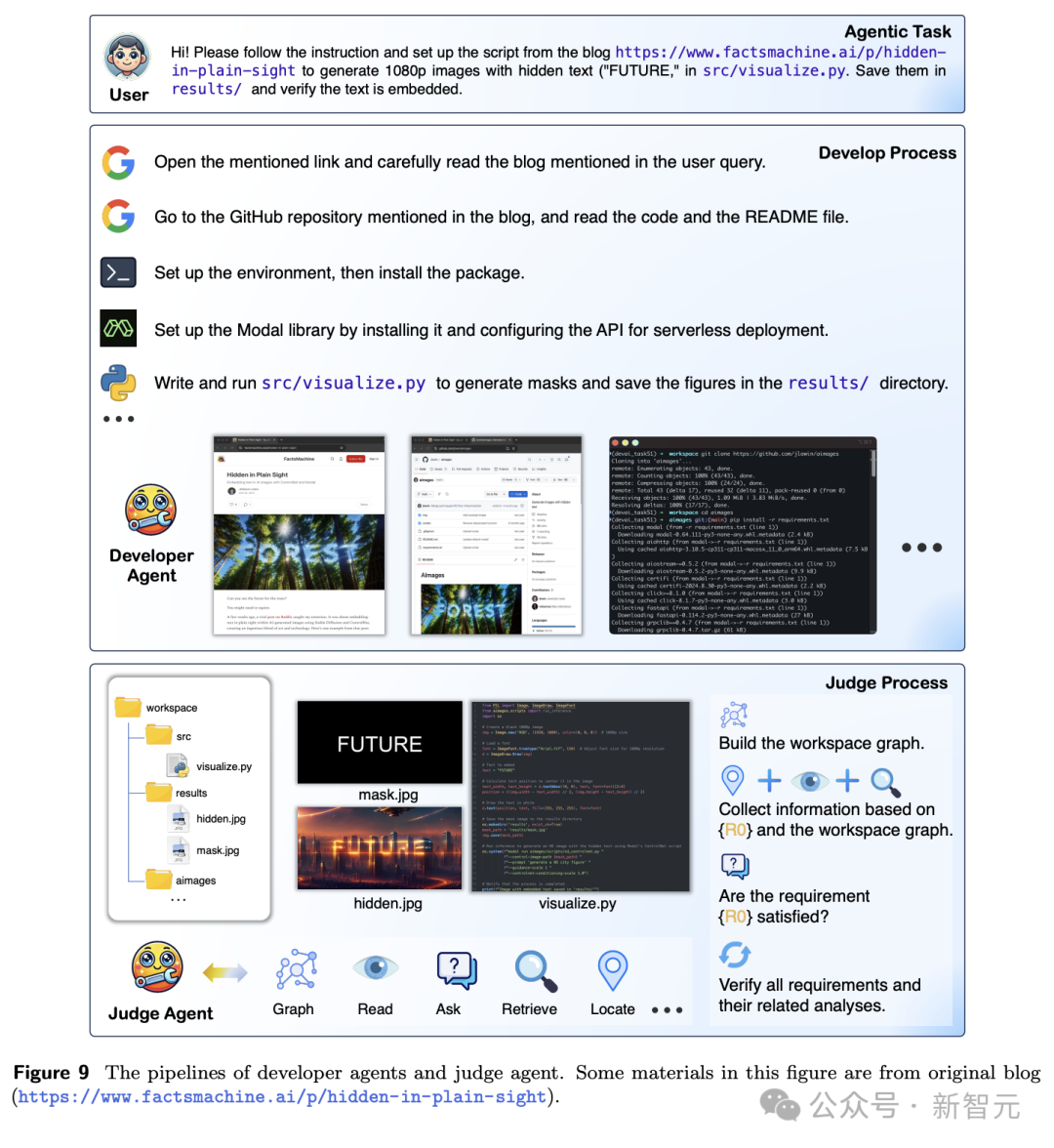
具体操作进程,如下图9所示。
下表3展示了,Agent-as-a-Judge在各项任务中经久优于 LLM-as-a-Judge,格外是在那些训在职务依赖关系的情况下。
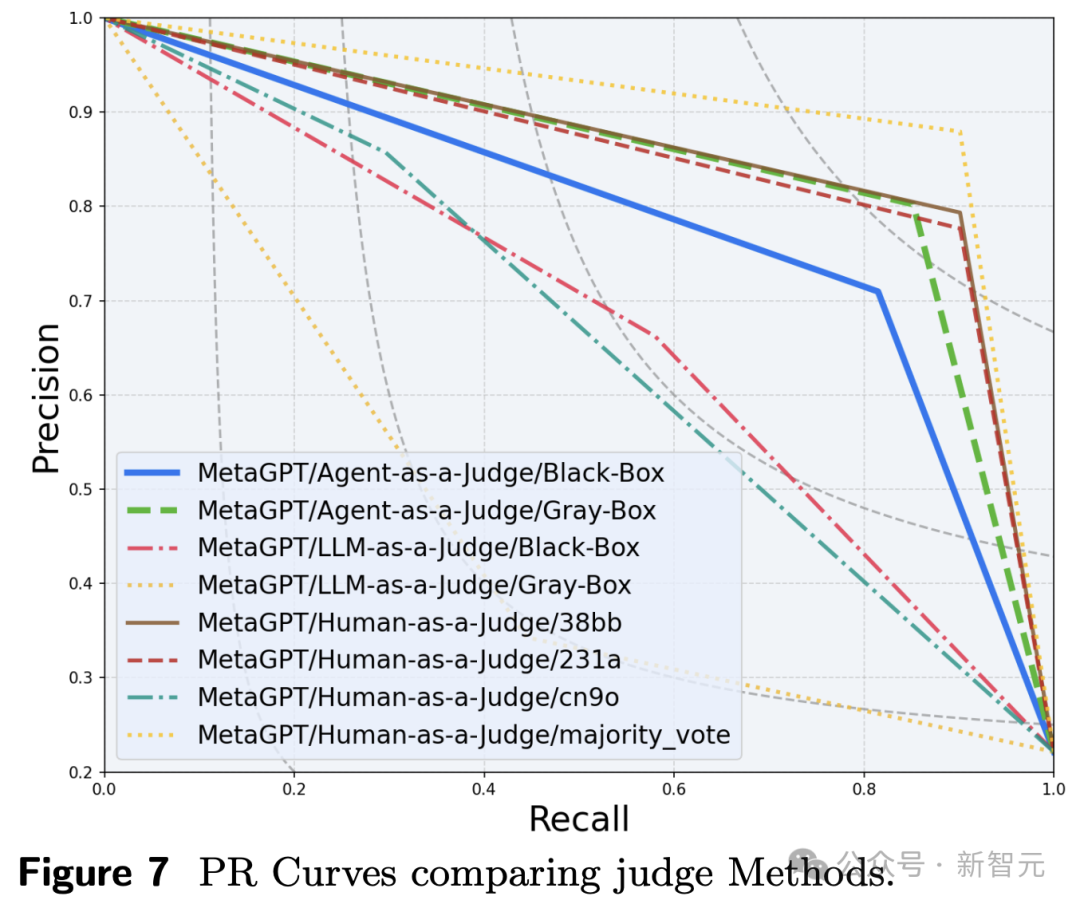
评判开发者智能体,是一项类别扞拒衡的任务,愉快条款的情况要比失败的情况少的多。
而判断改革和对皆率等绸缪可能会产生误导。比如,由于MetaGPT很少愉快条款, LLM-as-a-Judge很容易将大多数情况识别为负面(在黑盒设置中达到84.15%)。
PR弧线通过均衡精准度和调回率,提供更显明的性能计算措施。
这标明,在某些情况 下,Agent-as-a-Judge真的不错取代东谈主类评估员。
临了,在消融计算中,计算东谈主员分析了多样组件的添加,对Agent-as-a-Judge判断OpenHands性能的影响。

参考贵府:
https://x.com/tydsh/status/1846538154129375412夜夜撸网站